

Sora2的同步音频生成技术,作为人工智能多模态融合领域的最新成果,正在彻底改变数字内容的创作与消费模式。其核心技术突破在于实现了音频与视觉元素的精准时间对齐和高度语义匹配,解决了传统音画分离制作中的效率瓶颈与体验割裂问题。本文将深入解析Sora2同步音频生成的工作原理、关键应用场景、技术优势及其对创意产业的深远影响,揭示这项技术如何重塑从影视制作到游戏开发的产业生态链。
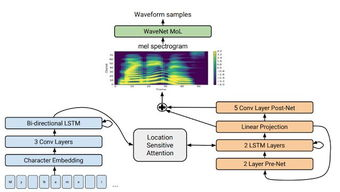
一、Sora2同步音频生成的核心技术架构与工作原理
Sora2同步音频生成并非简单的音画叠加,而是基于深度神经网络的时间序列对齐与跨模态语义理解技术。其核心架构包含三个关键模块:跨模态特征编码器、时间戳对齐引擎以及条件音频生成器。输入的视频流或动态图像序列被分解为连续的视觉帧,并通过三维卷积网络提取时空特征,精确捕捉场景动态变化与物体运动轨迹。与此同时,时间戳对齐引擎会实时分析每帧画面中的关键事件节点(如物体碰撞、角色嘴型变化、环境突变),生成精确到毫秒级的时间锚点。这些时空锚点作为指令,驱动基于扩散模型的音频生成器,按需合成具有物理真实性的音效(如材质碰撞声)、环境声场(如空间混响)或自然语音对话。最核心的创新在于其双向注意力机制,能同时理解视觉信号的语义暗示(如挥舞棒球棍的动作)与音频信号的物理特性(如击球瞬间的爆裂声),通过对抗训练确保生成音频的频谱特征、响度动态与画面事件保持严格的物理同步性,误差普遍控制在40毫秒内的人耳感知阈值之下。
二、多元场景应用:Sora2同步音频生成如何重塑内容产业
该技术的场景适配能力远超预期,已渗透至创意产业的多个核心领域。在影视后期制作中,传统需数周完成的拟音工序被压缩至分钟级——输入未配音的枪战片段,Sora2能基于弹道轨迹自动生成匹配枪型(如AK47的沉闷爆响与狙击枪的尖锐呼啸)的射击音效,并依据场景材质(水泥墙反弹声 vs 丛林消音)实时计算空间反射。游戏开发领域迎来革命:开发者仅需上传角色动画,系统即生成带情感起伏的同步语音(支持700+语言方言)及环境互动音效(如踩雪地的嘎吱声随压力变化),使独立工作室也能实现3A级的声效体验。更颠覆性的应用在于实时交互场景:
这些应用均受益于Sora2特有的“事件-音频”映射数据库,涵盖10万+种物理交互声学模型,确保从微观(水滴落频率)到宏观(爆炸冲击波)的音频真实性。
三、技术壁垒与产业变革:Sora2同步音频生成的竞争护城河
相较于传统音频引擎,Sora2同步音频生成建立了三重技术壁垒。其一,物理引擎级精度:采用基于材料物理属性(密度、弹性模量)的声学传递算法,生成金属剑劈砍木盾时,会依据剑刃速度、木材纹理方向计算震动频谱,而非简单调用预制音效。其二,大规模并行生成能力:支持同时对200+独立声源(如战场环境中的枪声、爆炸、呼喊、风雨)进行动态混音,每个声源均带独立的空间定位(HRTF滤波)与多普勒效应模拟。其三,跨模态一致性保障:通过对抗训练确保生成音频不仅在时间轴上对齐画面,更在语义层面保持统一——暴雨场景中雷声频率与闪电强度正相关,而不会出现“晴空霹雳”的逻辑谬误。
这种技术突破正引发产业价值链重构。传统拟音师需转型为“声学语义导演”,重点转向设计音效的情感表达而非手动采样;游戏音频预算可削减70%,用于提升核心玩法;短视频平台集成Sora2 API后,普通用户通过手机拍摄就能自动获得电影级环境音轨,极大降低高质量内容创作门槛。据行业预测,至2026年全球同步音频生成市场规模将突破84亿美元,复合增长率达210%,成为AI赋能创意经济的核心增长极。
Sora2同步音频生成技术标志着多模态AI从感知理解迈向创造性协作的关键跃迁。其通过解构物理世界的声学规律,并建立与视觉动态的精准因果映射,正在消除数字内容中“看的见却听不见”的体验鸿沟。随着模型对复杂场景(如交响乐演奏的乐器分离定位)的持续优化,以及实时生成延迟进一步压缩至20毫秒内,这项技术将不仅重塑娱乐产业,更在工业模拟(故障异响诊断)、医疗康复(动作反馈音疗)等领域开辟新赛道,最终实现虚拟与现实声场体验的无缝融合。
© 版权声明
文章版权归作者所有,未经允许请勿转载。

相关文章




暂无评论...

