

在数字支付已成为核心商业基础设施的今天,支付系统的高可用性直接关系到企业的资金安全、用户体验乃至品牌声誉。一个满足严苛高可用标准的支付架构,意味着即使在硬件故障、流量激增或区域灾难等极端场景下,系统也能持续提供可靠服务。本文将深入探讨构建支付系统高可用性的核心原则、关键技术组件与实战化运维策略,为打造韧性十足的金融基础设施提供系统化方案。
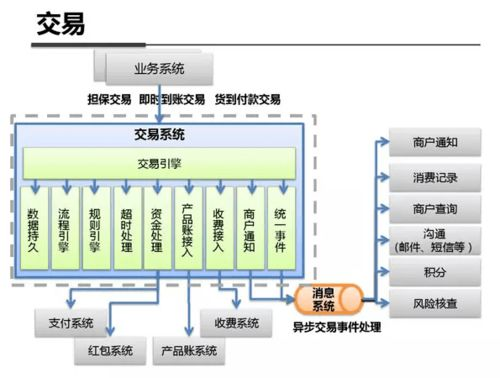
高可用支付系统的核心架构设计与容错机制
构建高可用支付系统的首要原则是消除单点故障。采用分布式架构设计,通过多地域多可用区部署服务节点,如支付宝采用的单元化架构(LDC),将用户流量按维度划分到独立单元。关键组件如交易引擎采用主备集群部署,结合Paxos/Raft等共识算法实现强一致性,确保主节点宕机时秒级切换。数据库层面通过MySQL MGR或Redis Cluster构建读写分离集群,配合分库分表策略(如ShardingSphere)分散压力。在通讯层,部署双活API网关集群并配置动态路由,结合负载均衡器(如Nginx Plus+Keepalived)实现流量自动切换。支付系统的核心资金账户服务需实现异地双活,通过异步复制+最终一致性模型,在CAP理论中优先保障分区容忍性(P)与可用性(A),允许特定场景下短暂数据延迟但绝不丢失交易请求。
全链路监控与自动化故障处置体系
实时监控是高可用支付系统的神经系统。需建立覆盖四层黄金指标(延迟、流量、错误、饱和度)的立体化监控:
应用层:通过Java Agent植入SkyWalking实现全链路追踪,对支付核心路径(支付创建->风控->渠道路由->记账)设置500ms超时熔断规则。对支付错误码进行精细化分类监控,特别是对资金相关错误(如余额不足双写不一致)配置P1级报警。
构建自动化故障处置平台是保障持续可用的关键。当支付网关检测到某支付渠道成功率骤降时,自动触发渠道切换策略,将交易路由至备用通道;当数据库主节点响应延迟超过200ms,由管控平台自动执行主备切换并重建复制关系;对于突发流量冲击,通过Hystrix实现服务熔断降级,暂时关闭非核心的营销返现功能,保障支付主链路通畅。
灾备体系构建与常态化演练机制
符合金融级标准的支付系统需建立多层级灾备方案:
异地容灾:在≥500km外的城市建立备份数据中心,采用异步复制模式(RPO≤5分钟),当主中心发生区域性故障(如电力中断)时,30分钟内完成业务切换,满足PCI-DSS的RTO要求。
实施严格的混沌工程演练是检验高可用性的试金石。每月执行蓝军攻防演练:随机终止支付核心容器节点,验证K8s重建能力;模拟数据中心网络隔离,测试跨区容灾切换流程;对账务系统注入CPU高压,检查限流降级策略有效性。演练后需生成《支付系统韧性评估报告》,持续优化故障预案(如优化支付状态机补偿机制)。
支付系统的高可用建设是永无止境的征程,需要从架构设计之初就注入韧性基因,通过分布式部署消除单点、智能监控实现秒级感知、自动化处置降低MTTR、常态化演练验证预案有效性。当这些技术手段与完善的金融级运维流程(如变更三板斧、灰度发布)相结合,才能使支付系统真正达到99.995%的可用性标准,即全年故障时间不超过26分钟,为每笔支付交易构筑坚不可摧的技术防线。尤其对于日均处理亿级交易的支付平台,高可用架构不仅是技术选项,更是企业生存发展的核心竞争力。
© 版权声明
文章版权归作者所有,未经允许请勿转载。

相关文章





暂无评论...

