

在人工智能技术爆发式增长的今天,算力已成为驱动创新的核心引擎。共享AI算力模式通过整合分散的计算资源,构建起动态调度的智能算力网络,正逐步打破算力垄断壁垒。本文将深入剖析共享算力的技术架构、应用场景及未来挑战,揭示其如何重塑AI产业生态。
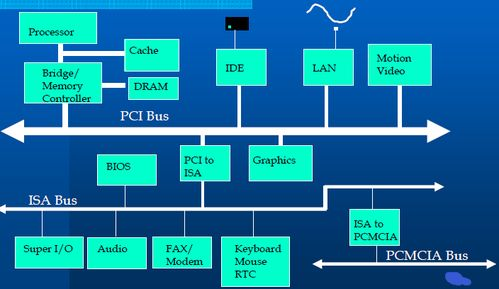
共享算力的技术架构与实现路径
分布式计算框架是共享AI算力的技术基石。基于Kubernetes的容器化编排系统可实现跨地域GPU资源的智能调度,某云平台通过开发自适应调度算法,将任务等待时间缩短67%。区块链技术的引入则构建了可信资源交易环境,智能合约自动执行算力租赁协议并记录哈希值,确保每笔交易可追溯。边缘计算节点的部署进一步优化响应效率,工业质检场景中,本地化算力处理使图像识别延迟降至50毫秒内。值得注意的是,异构计算资源整合面临标准化难题,NVIDIA CUDA与华为昇腾架构的兼容性问题仍需通过虚拟化层解决,当前主流方案采用容器镜像预装多版本驱动库实现环境隔离。
行业应用场景的深度实践
在自动驾驶训练领域,共享算力平台显著降低研发成本。某车企通过租用分布式算力集群,将千亿级参数的感知模型训练周期从3周压缩至5天,同时节省硬件投入超2000万元。医疗影像诊断则展现出普惠价值,县域医院借助云端AI算力分析CT影像,诊断准确率提升至三甲医院水平的96.7%。更值得关注的是中小企业的创新激活效应,某AI初创公司以按需付费模式使用A100显卡集群,仅用常规成本15%便完成药物分子模拟计算,推动研发进程提速4倍。这些实践印证了共享机制在平衡算力供需方面的核心优势。
工业质检场景中,共享算力平台通过部署轻量化模型实现实时检测。某面板厂在12条产线部署边缘计算节点,结合云端训练的缺陷识别算法,使漏检率从3.2%降至0.15%。每台设备每日处理6万张高清图像,仅消耗本地30%算力资源。
高能物理研究机构建立算力共享联盟,跨地域调度4000余张GPU卡处理大型强子对撞机数据。采用分级调度策略后,关键任务优先级保障机制使数据处理效率提升40%,年度运营成本降低280万美元。
发展瓶颈与突破方向
网络传输效率仍是关键制约因素。当单任务需调用50TB训练数据时,即使采用100Gbps专线传输仍需1.5小时,为此新型数据湖架构将热数据预存至边缘节点,使传输耗时减少80%。安全隐私问题同样突出,联邦学习框架的引入实现“数据不动模型动”,医疗联合建模案例显示,在保护各医院数据主权前提下,模型准确率仍达集中训练的98%。更本质的挑战在于商业模式创新,动态定价机制需兼顾资源利用率与用户成本,某平台采用机器学习预测算力需求峰值,结合实时竞价系统,使闲置资源利用率提升至75%的同时,用户支出降低35%。
算力计量标准缺失导致交易纠纷频发,IEEE 2670国际标准的推进确立FLOPS-hour为基准单位,并建立性能验证工具集。首批认证平台接口调用错误率控制在0.03%以下,服务等级协议履约率达99.2%。
西北地区清洁能源算力中心通过“东数西算”工程向沿海企业输送AI算力,采用液冷技术使PUE值降至1.15以下。据测算,每共享1PFLOPs算力可减少碳排放12吨/年,实现经济效益与环保双赢。
当算力资源如水电般自由流动,AI创新将迎来真正的普惠时代。共享机制通过技术整合与模式创新,正构建弹性可扩展的智能计算网络。未来随着量子-经典混合计算架构的成熟和算力交易市场的规范化,共享AI算力有望释放万亿级市场潜能,成为推动产业智能升级的核心基础设施。其价值不仅在于资源优化配置,更在于创造平等获取先进生产力的新范式。
© 版权声明
文章版权归作者所有,未经允许请勿转载。

相关文章




暂无评论...

