

在人工智能技术迅猛迭代的浪潮中,生成式预训练模型(GPT)作为自然语言处理领域的革命性突破,正推动通用人工智能(Artificial General Intelligence, AGI)向实用化阶段迈进。本文将深入解析其技术内核、应用边界与未来挑战,揭示其如何重塑人机交互范式。
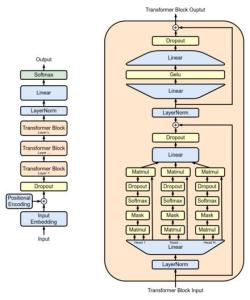
生成式预训练模型的技术架构与演进路径
生成式预训练模型的核心在于Transformer架构与海量语料训练的双轮驱动。通过自注意力机制实现对文本深层语义的捕捉,模型在预训练阶段学习语言表征规律,微调阶段则针对特定任务优化。从GPT-3的1750亿参数到GPT-4的混合专家系统(MoE),参数量与模型结构的协同进化显著提升了上下文理解与逻辑推理能力。值得注意的是,模型涌现出的零样本学习(Zero-shot Learning)特性,使其在面对未训练任务时仍能生成合理输出,这标志着通用人工智能的重要里程碑。当前技术攻坚点聚焦于知识实时更新机制与多模态融合,通过检索增强生成(RAG)技术连接动态知识库,以及视觉-语言跨模态对齐研究。
通用人工智能实践场景的颠覆性重构
生成式预训练模型正深度重构产业生态。在内容创作领域,AI写作工具可自动生成符合SEO规范的千字长文,同时保持语义连贯性与关键词密度平衡;在编程开发中,GitHub Copilot基于代码理解实现自动补全,将开发效率提升55%以上;医疗诊断辅助系统则能解析患者主诉生成初步诊断报告。更值得关注的是其在复杂决策系统的渗透:金融领域利用GPT模型分析政策文本预测市场波动,制造业通过操作手册自动生成设备维护方案。这些应用验证了模型在跨领域任务中的泛化能力,但需警惕过度依赖导致的认知惰性风险。
伦理治理与技术瓶颈的双重挑战
伴随生成式预训练模型的指数级发展,三大核心矛盾亟待破解:
训练语料中的性别、种族偏见可能被模型强化,需通过对抗性去偏算法与人工审核闭环改进
单次GPT-4训练耗电量相当于1300户家庭年用电量,亟需发展稀疏化训练与神经架构搜索技术
AI生成内容的版权归属与错误追责机制尚未建立,欧盟AI法案要求强制标注生成内容仅是初步尝试
技术层面则面临逻辑链断裂问题:当处理超过万字的复杂文档时,模型仍会出现事实矛盾,这需要记忆增强架构与符号逻辑系统的融合创新。
生成式预训练模型正成为通用人工智能的基础设施,其突破性进展已超越纯技术范畴,引发社会生产关系重构。未来五年将进入”模型即服务”(MaaS)时代,开发者可通过API调用垂直领域微调模型。但技术民主化进程需同步建立伦理框架,包括开发可解释性工具包、构建人类价值观对齐机制。唯有平衡创新与治理,方能使gpgpt技术真正赋能人类文明跃迁。
© 版权声明
文章版权归作者所有,未经允许请勿转载。

相关文章




暂无评论...

