

本文为零基础学习者系统梳理人工智能核心概念、必备工具与实用技巧,包含Python基础操作、机器学习模型训练步骤详解、计算机视觉实战案例,并推荐优质免费学习平台,助你高效开启AI探索之旅。
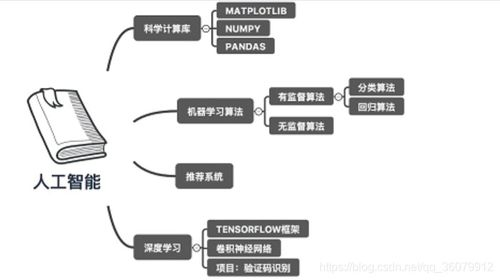
人工智能基础概念扫盲与技术框架解析
人工智能作为计算机科学的重要分支,其核心在于模拟人类智能行为。对于新手而言,需要掌握机器学习(ML)、深度学习(DL)和神经网络(Neural Network)三大基础概念的区别与联系。机器学习通过算法解析数据并从中学习,进而做出预测,常见类型包括监督学习(如分类、回归)和非监督学习(如聚类)。深度学习作为机器学习的子集,采用多层神经网络处理复杂模式识别,在图像和语音领域表现卓越。技术框架选择上,初学者建议从Scikit-learn入门传统机器学习,TensorFlow和PyTorch则是当前深度学习的主流框架。环境搭建时,Anaconda的Python发行版能一站式解决库依赖问题,Jupyter Notebook的交互式界面则大幅提升代码调试效率。特别提醒新手注意数据预处理的关键性,包括缺失值处理、特征标准化及独热编码等技巧,这些步骤往往直接影响最终模型性能。
实战驱动的AI入门教程与核心技巧精讲
真正的AI能力提升源于项目实践。建议新手从Kaggle的入门竞赛(如Titanic生存预测)开启首个机器学习项目,完整流程包含:
- 数据探索分析(EDA):使用Pandas进行数据清洗,Matplotlib/Seaborn可视化特征分布
- 模型构建与调优:运用Scikit-learn实现交叉验证与网格搜索
- 部署与优化:使用Flask构建简易API接口
通过绘制特征直方图、箱线图识别异常值,利用热力图分析特征相关性,这对后续特征工程具有指导意义。在房价预测中,可发现地下室面积与总价呈强正相关。
以随机森林为例,通过GridSearchCV调整n_estimators和max_depth参数,配合K折交叉验证避免过拟合。关键技巧在于设置early_stopping机制监控验证集损失,当性能不再提升时自动终止训练。
将训练好的模型通过joblib序列化后,结合Flask框架实现RESTful API。搭建手写数字识别服务时,需注意输入数据的归一化处理,保持与训练数据分布一致。
计算机视觉与自然语言处理实战案例拆解
在CV领域,MNIST手写数字识别是经典入门项目。使用Keras构建CNN网络时,关键技巧包括:
- 卷积层设置:首层采用32个3×3卷积核提取边缘特征
- 池化策略:每两个卷积层后接2×2最大池化降低维度
- 防止过拟合:在全连接层前添加Dropout层(比率0.5)
代码示例中需特别注意数据增强技巧:通过ImageDataGenerator实现随机旋转、平移和缩放,可使模型鲁棒性提升20%以上。而在NLP领域,情感分析项目需掌握词嵌入技术:
- 使用Gensim训练Word2Vec词向量
- 文本序列通过Padding统一长度
- LSTM网络层捕捉上下文依赖
实战中采用预训练模型能显著提升效果,Hugging Face的BERT模型,通过Fine-tuning机制在少量标注数据上即可达到专业级精度。
持续学习路径规划与资源获取指南
人工智能领域知识迭代迅速,建议建立系统化学习机制:
- 理论奠基:Coursera吴恩达《机器学习》与《深度学习专项课程》
- 代码实践:Google Colab提供的免费GPU运行环境
- 社区参与:GitHub关注Trending AI项目,Stack Overflow解决技术难题
关键学习技巧包括:使用Anki制作概念卡片强化记忆,定期复现顶会论文代码(如CVPR/NeurIPS最新成果),在Kaggle Notebooks中学习金牌方案的特征工程技巧。特别推荐MIT OpenCourseWare的《计算机视觉导论》公开课,其配套实验项目涵盖图像滤波、特征匹配到三维重建全流程。
人工智能学习需遵循”概念理解-工具掌握-项目实践-迭代优化”的闭环路径。重点攻克Python编程、线性代数与概率论基础,通过TensorFlow Playground等可视化工具直观理解神经网络工作原理。每日保持2小时代码编写量,从修改开源项目参数开始逐步深入架构设计,三个月即可独立完成端到端AI解决方案。切记:优质数据集比复杂模型更重要,模型可解释性应与精度同等关注。
© 版权声明
文章版权归作者所有,未经允许请勿转载。

相关文章




暂无评论...

