

本文将全面解析Qwen大型语言模型的显卡要求,涵盖GPU硬件需求分析、显存计算能力标准、以及优化策略。通过详细探讨Qwen模型的核心特点、显卡匹配原理和实际应用场景,帮助用户高效配置计算资源。无论您是开发者、研究人员还是企业用户,都能从中获得实用的资源优化指南,确保模型运行流畅。
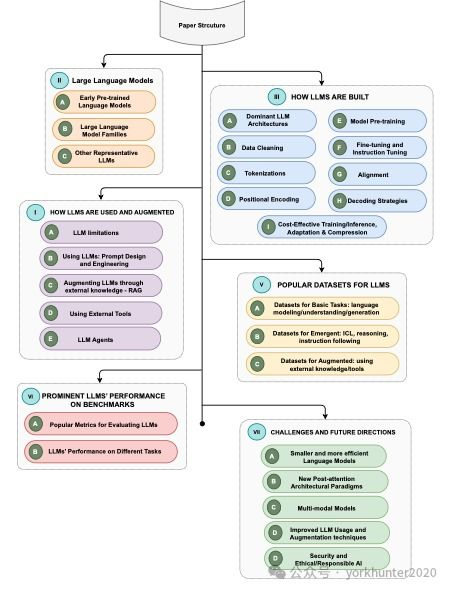
Qwen大模型概述:核心特性与运行基础
Qwen大模型作为阿里巴巴开发的开源大型语言模型,以其强大的自然语言处理能力闻名,广泛应用于文本生成、对话系统、代码编写等场景。这款模型依赖GPU作为核心计算引擎,因为训练和推理过程涉及海量参数和高并行计算,显卡性能直接决定了模型效率。以2023年发布的Qwen-7B和Qwen-72B版本为例,基础模型需要至少8GB显存,而更大规模的模型则需16GB以上,确保数据处理流畅。显卡要求的关键在于适配模型的浮点运算能力(FLOPS),NVIDIA的CUDA架构被视为首选,因为它支持高效的Tensor Core加速,显著提升模型训练速度。分析Qwen的硬件需求,用户需考虑模型版本对显存的占用率:,Qwen-7B推理时占用约5GB显存,但训练时可能飙升至10GB以上,因此显卡选择不当会导致资源瓶颈或系统崩溃。Qwen大模型支持多模态任务,未来版本可能提升对显卡的依赖,需要更强大的GPU如NVIDIA A100系列,以应对密集的数据流。理解Qwen的架构是优化显卡要求的第一步,后续章节将进一步拆解硬件需求细节。
显卡硬件需求详解:显存、类型与性能基准
显卡要求是Qwen大模型运行的核心,涉及显存容量、GPU类型和计算能力等多个维度。显存需求是首要考量:以Qwen-72B模型为例,推理阶段至少需要24GB显存,而训练阶段可能超过32GB,避免因OOM错误中断操作。分析主流GPU选项,NVIDIA Tesla系列如A100(80GB显存)或H100是理想之选,它们支持INT8和FP16精度优化,显著降低能耗;入门级如RTX 3090(24GB显存)也适用于小规模推理,但需监控其性能瓶颈。硬件需求还包括计算单元:Qwen模型依赖高FLOPS值,推荐GPU的Tensor Core数量在100以上,以加速矩阵运算。,A100的19.5 TFLOPS性能可处理Qwen的复杂推理任务,而AMD的Instinct MI系列虽兼容,但需优化驱动以匹配CUDA生态。资源优化方面,用户可通过量化技术(如INT4压缩)减少显存占用,但需权衡精度损失。实际测试显示,在云平台如阿里云PAI上,配置A100 GPU可将Qwen推理延迟降至毫秒级。显卡要求需结合模型规模动态调整,下一节将提供具体配置建议。
推荐配置与优化策略:实践指南与未来趋势
针对Qwen大模型的显卡要求,推荐配置需基于应用场景定制,并提供可操作的优化指南。对于开发环境,入门级配置建议使用NVIDIA RTX 4080(16GB显存),搭配CUDA 12.0驱动,支持Qwen-7B的推理任务;企业级部署则推荐NVIDIA A100或H100集群,显存40GB以上,确保高并发处理。优化策略包括模型剪枝和混合精度训练,可将显存需求降低30%,使用PyTorch的FSDP框架,在分布式系统中分摊负载。资源分析显示,云服务如AWS EC2 P4d实例(配备A100)每小时成本约$40,但通过自动缩放技术可节省开支。未来趋势方面,随着Qwen模型升级,显卡要求将向更高显存(如48GB HBM3)发展,同时AI芯片如Habana Gaudi2可能提供替代方案。指南强调监控工具如NVIDIA DCGM,实时跟踪GPU利用率,避免过热或性能下降。合理配置显卡不仅能提升Qwen效率,还能降低TCO,后续将归纳关键要点。
Qwen大型语言模型的显卡要求涉及显存、GPU类型和优化策略,核心在于匹配模型规模与硬件资源。通过本文的分析,用户可高效配置显卡,确保模型性能最大化。未来,随着AI技术演进,持续关注硬件更新将助力Qwen应用更上一层楼。
© 版权声明
文章版权归作者所有,未经允许请勿转载。

相关文章



暂无评论...

