
谷歌TPU(Tensor Processing Unit)作为专为机器学习负载设计的定制硬件,其强大的算力释放离不开完善的工具链支持。本文将深入解析谷歌TPU工具链的核心组件、工作流程与最佳实践,涵盖从模型开发、编译优化到集群部署的全套解决方案,助您高效驾驭这一高性能计算平台。
谷歌TPU硬件架构与基础工具链解析
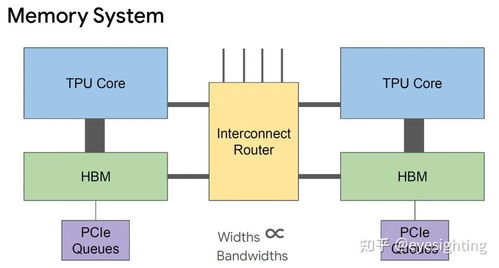
谷歌TPU采用脉动阵列架构,专为矩阵运算优化,其工具链围绕TensorFlow生态深度构建。核心组件包括Cloud TPU虚拟机实例、TPU运行时库(libtpu)及资源管理器。用户通过Google Cloud Console或gcloud CLI创建TPU节点时,系统自动配置专用驱动和网络栈。TPU v4/v5e机型支持bf16/f32混合精度计算,工具链通过XLA编译器自动优化精度转换。关键开发工具tf.distribute.TPUStrategy实现数据并行训练,只需数行代码即可将单机模型迁移至TPU Pod。本地调试推荐使用Colab TPU运行时,配合tf.config.experimental_connect_to_cluster()实现无缝验证。值得注意的是,TPU内存模型与GPU不同,工具链通过TPUEmbedding API优化稀疏特征处理效率,减少主机-设备数据传输开销达70%以上。
XLA编译器与模型优化工具实战
XLA(Accelerated Linear Algebra)是TPU工具链的核心编译器,其工作流程包含三个阶段:
- 前端转换: 将TensorFlow/PyTorch(JAX)计算图转化为HLO(High-Level Optimizer)中间表示
- 设备级优化: 针对TPU架构的特定优化
- 后端代码生成: 生成TPU可执行指令
使用tf.function(jit_compile=True)触发自动图优化,HLO通过融合操作符(如Conv-BN-ReLU)减少内核启动次数。典型ResNet50训练中,XLA可将迭代时间缩短40%
包括内存空间布局转换(Layout Assignment)、分片策略优化(Sharding Propagation)以及集体通信优化。工具链提供tf.tpu.experimental.embedding模块自动处理嵌入表分区,支持table-wise/column-wise分片策略
通过TPU Compiler (tpu-compiler) 生成LLVM IR,最终输出TPU指令集。开发者可使用tf.profiler.experimental.Trace监控编译耗时,结合Cloud Monitoring设置编译时间告警阈值
生产环境部署与运维管理
谷歌TPU工具链提供完整的MLOps解决方案:
- Vertex AI集成: 通过预构建TPU训练容器(如tf_2.15.0-tpu)实现一键式流水线
- 性能监控套件: 内置Profiler工具集
- 弹性伸缩策略: 基于负载的动态资源配置
支持自定义Docker镜像推送至Artifact Registry,利用Vertex Pipelines配置分布式训练参数,最大支持2048个TPU v4芯片的Pod切片
使用tf.profiler.experimental.client.trace()捕获TPU执行轨迹,可检测到矩阵乘法单元利用率不足、主机-设备通信瓶颈等问题。Cloud Logging中预设TPU_DRIVER_ERROR等关键指标看板
通过TPU API的tpu.googleapis.com/v1alpha1接口实现自动扩缩容,结合抢占式实例(Preemptible TPU)可降低60%训练成本。推荐设置Checkpoint保存间隔不超过30分钟以应对实例回收
谷歌TPU工具链通过深度集成的软件栈与自动化管理能力,显著降低高性能硬件使用门槛。从XLA编译优化到Vertex AI全托管服务,开发者可专注于模型创新而非基础设施运维。随着TPU v5e的全面上市及开源框架支持扩展,该工具链将持续赋能AI工程化落地,为大规模模型训练提供端到端的解决方案。
© 版权声明
文章版权归作者所有,未经允许请勿转载。

相关文章





暂无评论...

